
记录es一次死锁问题排查
1、问题概述
业务流程
1、从kafka消费数据。
2、业务解析,组装数据。
3、将组装好的数据,使用bulkProcessor.add(indexRequest),异步批量提交数据到ES。
问题描述
kafka消费延迟监控报警,发现某个topic消费延迟持续增长,我们查看日志的时候,发现服务消费该topic消息的日志信息没有。分析ES的ECS的服务器情况,发现插入消息的总量陡降低。如下: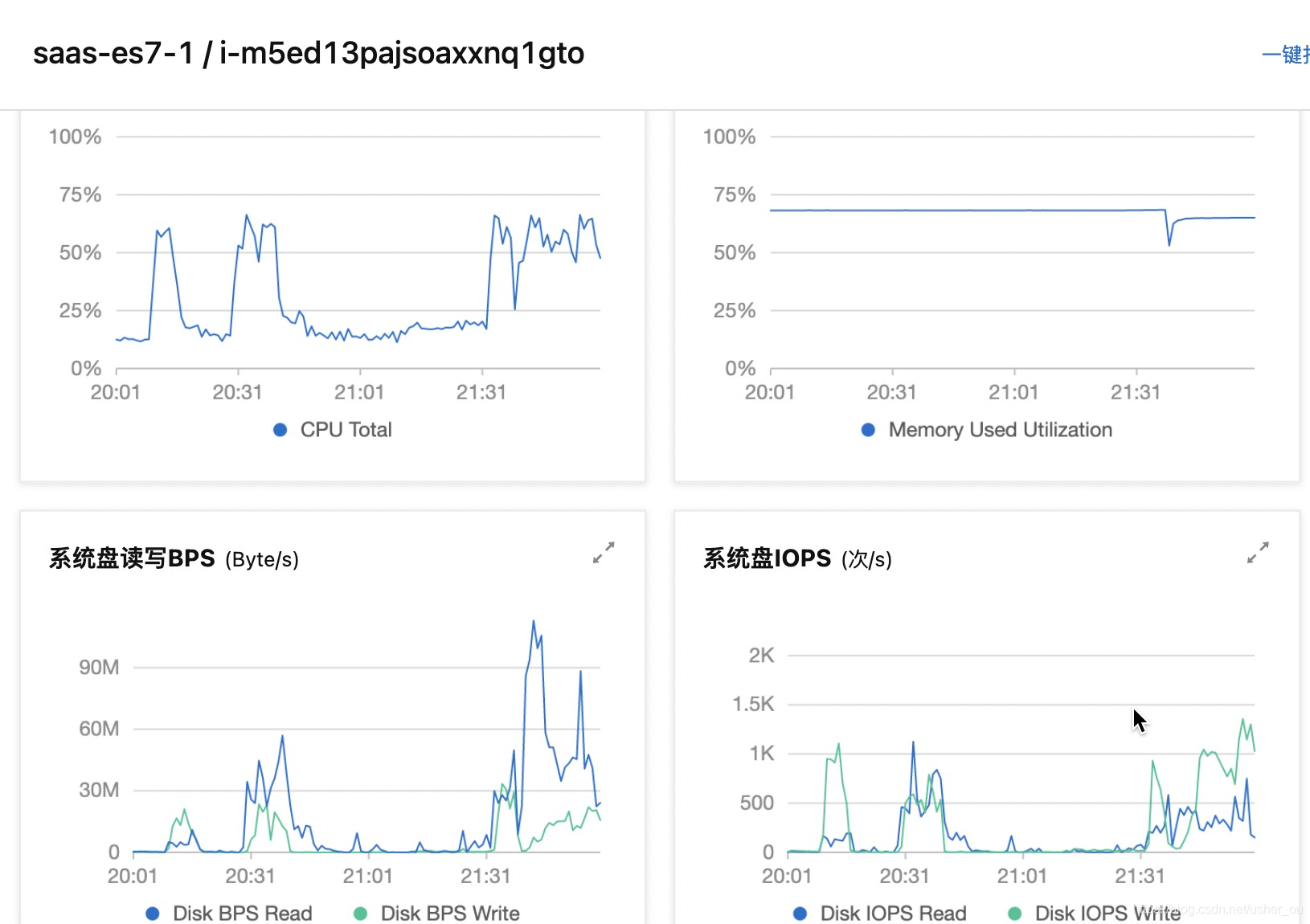
线程jstack信息
第一步查看进程 ps aux |grep java
第二步查看当前进程CPU占用情况top -Hp pid,发现线程资源占用都很平均
第三步打印查看当前进程jstack分析,jstack 29192 > 1.text
直接搜索BulkProcessor关键字,发现大量相关线程处于WAITING(parking)阻塞状态,- parking to wait for <0x0000000727e62228> (a java.util.concurrent.locks.ReentrantLock$NonfairSync)也就是说代码阻塞在ReentrantLock等待对象锁: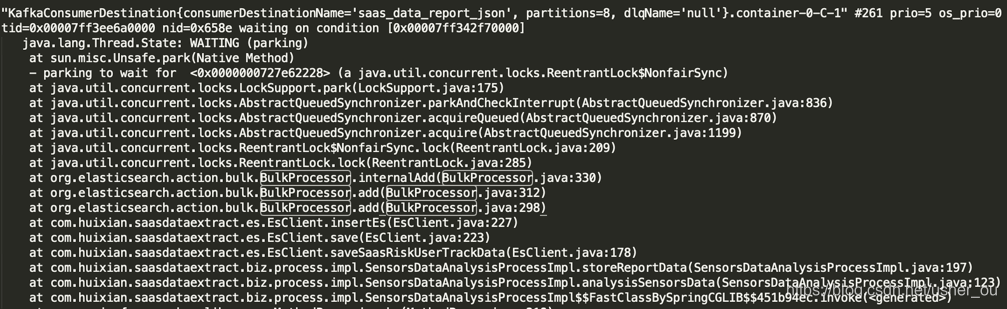
2、问题排查
BulkProcessor执行流程

源码梳理
- org.elasticsearch.action.bulk.BulkProcessor
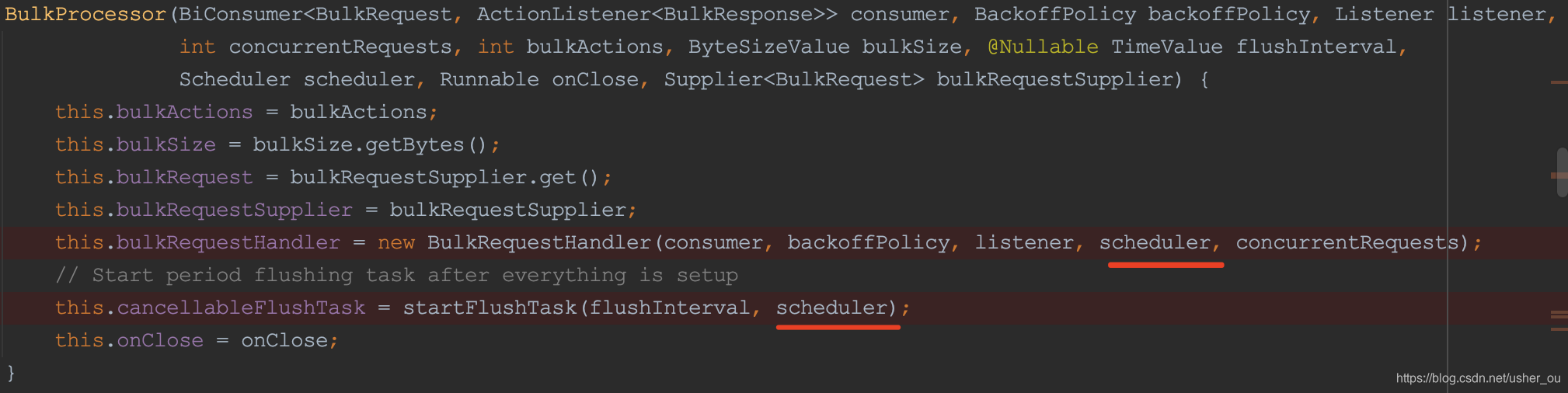
Scheduler核心线程数 == 1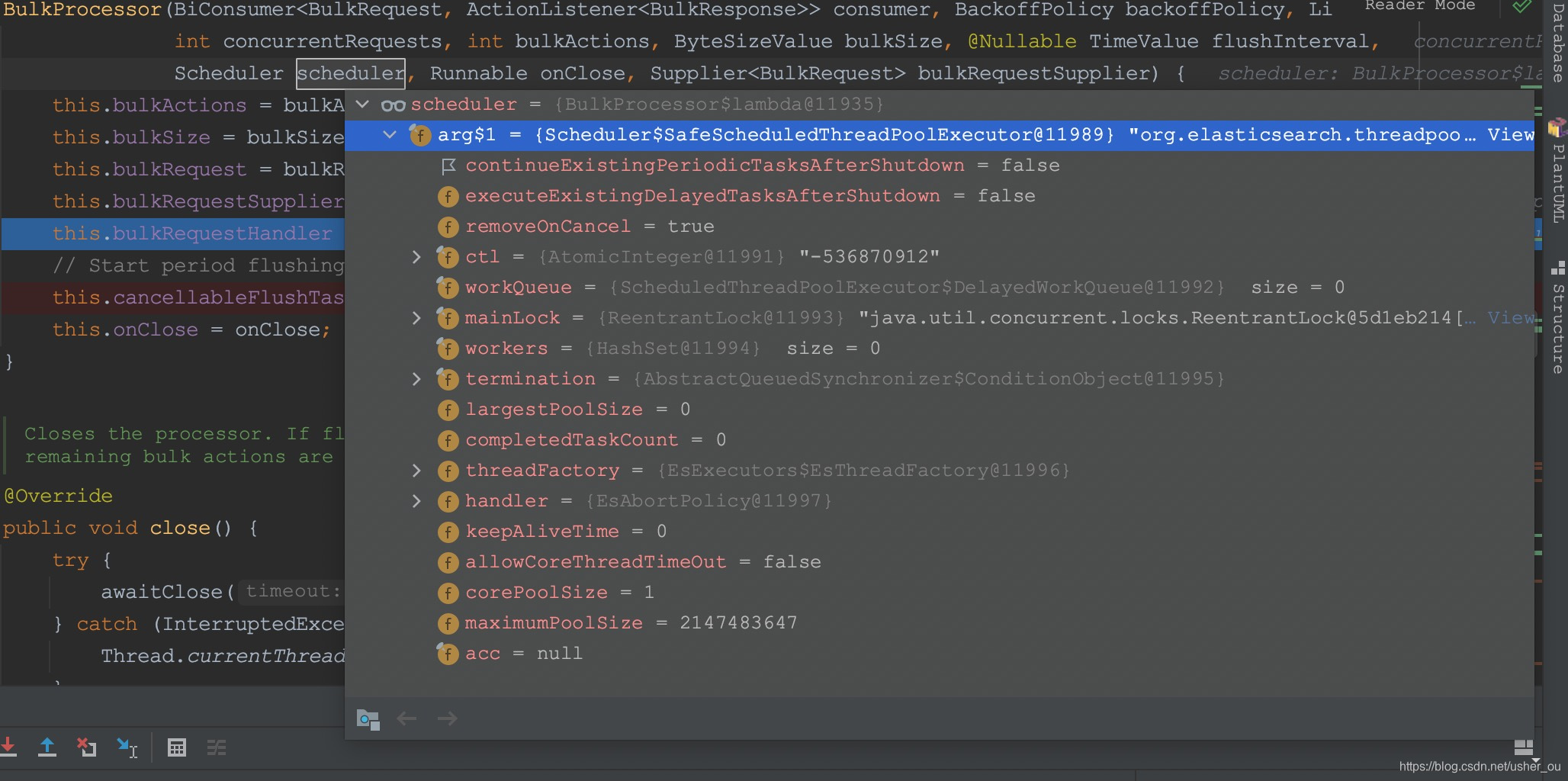
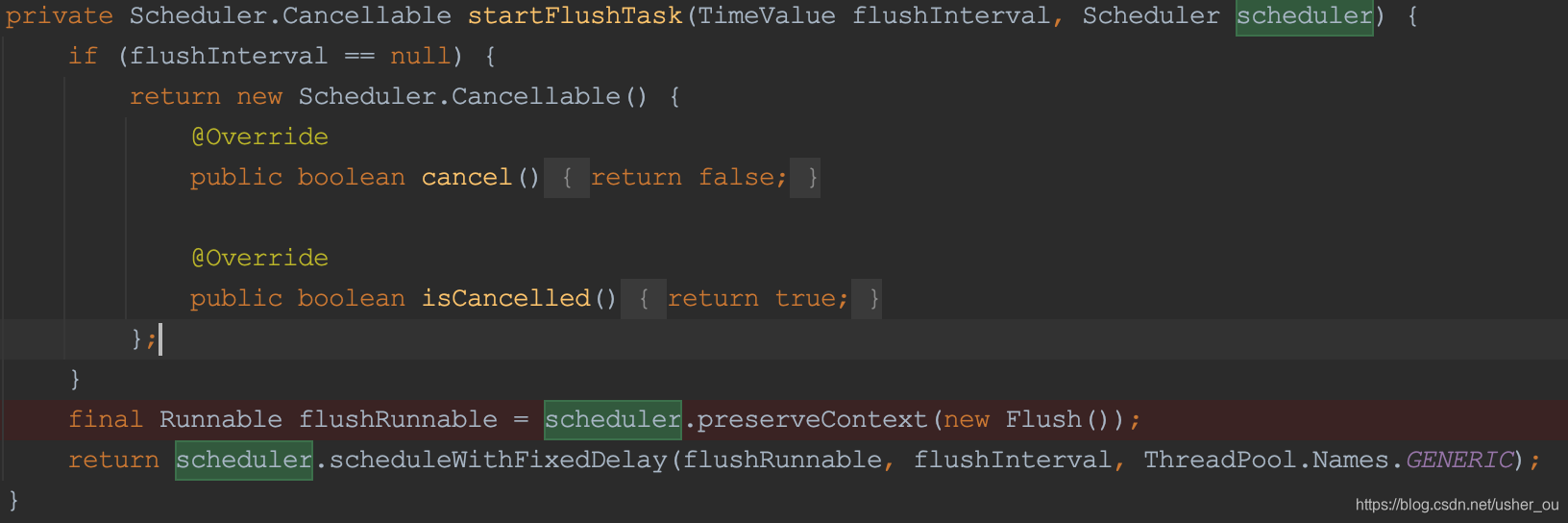
传入的scheduler一被用作BulkRequestHandler的构造方法,一被startFlushTask用来构造Flush Thread。但是schedule的本身的corePoolSize=1,只有一个线程,所以Flush和BulkRequestHandler注定在同一时刻只能有一个能使用schedule进行操作
- schedule on org.elasticsearch.action.bulk.Retry
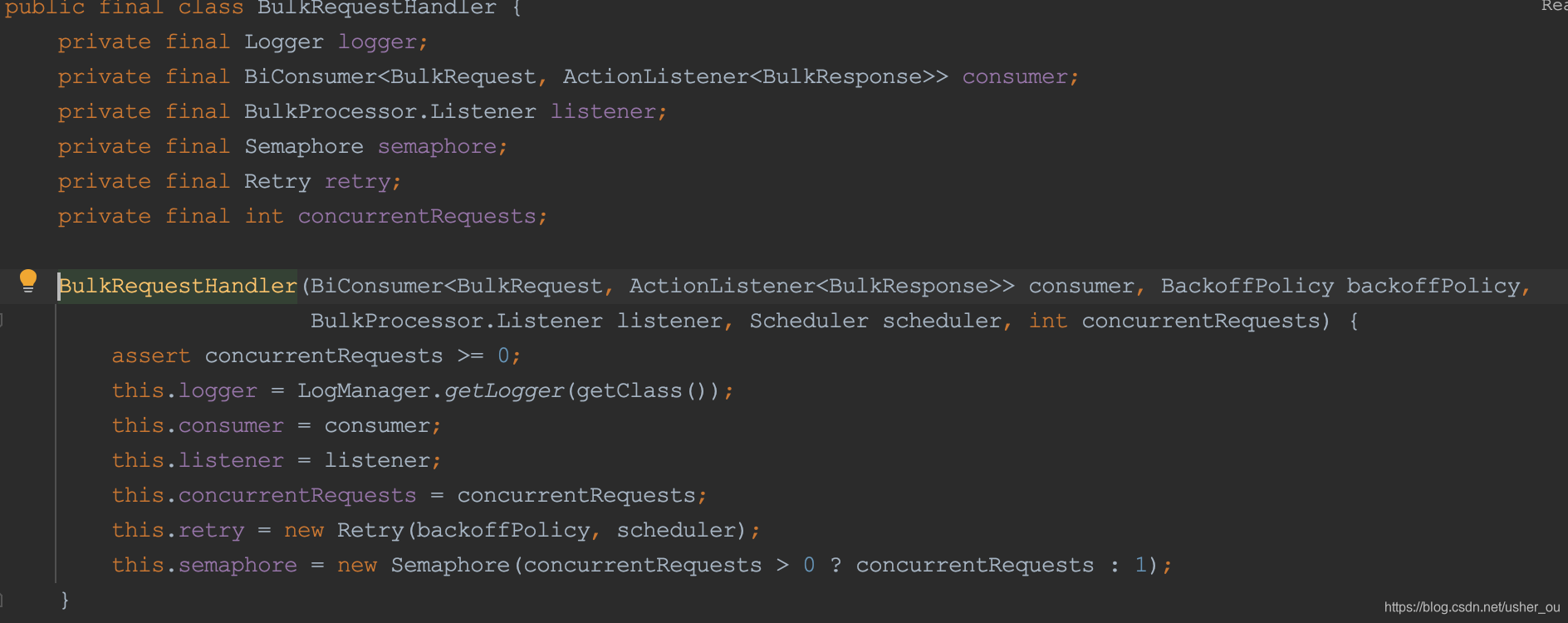
- schedule on org.elasticsearch.action.bulk.Retry

初始化Retry对象的Scheduler是同一个Scheduler对象。
- org.elasticsearch.action.bulk.BulkRequestHandler—核心代码

死锁逻辑梳理
- 步骤1
org.elasticsearch.action.bulk.BulkProcessor#internalAdd 执行org.elasticsearch.action.bulk.BulkProcessor#execute方法,执行前使用semaphore.acquire()获取锁,执行完成后的回调中使用semaphore.release()释放锁。
此时达到执行internalAdd数据量大小的条件,去调用ES插入数据,但是ES超时触发重试。
- 步骤2
基于scheduler和org.elasticsearch.action.bulk.BulkProcessor.Flush构造的定时flush的任务因为达到时间间隔开始执行(scheduler的核心线程池大小是1,已经被正在执行flush任务占用了)。flush的任务最终也是调用org.elasticsearch.action.bulk.BulkProcessor#execute方法,所以flush任务尝试获取锁,但是这时候步骤1还没有执行完成,锁还在执行internalAdd。
- 步骤3
调用ES插入触发异常,导致部分写入失败了,需要执行重试逻辑;请求结束后,调用org.elasticsearch.action.bulk.Retry.RetryHandler#onResponse方法,发现了部分失败且能够重试的数据,执行org.elasticsearch.action.bulk.Retry.RetryHandler#retry方法,但是这个retry的执行逻辑是基于scheduler的,而scheduler的核心线程数是1,此时已经被flush占用了,导致retry根本没有执行。而retry不执行,步骤1持有的锁就不会释放。
3、解决办法
升级elasticsearch的版本为7.6.0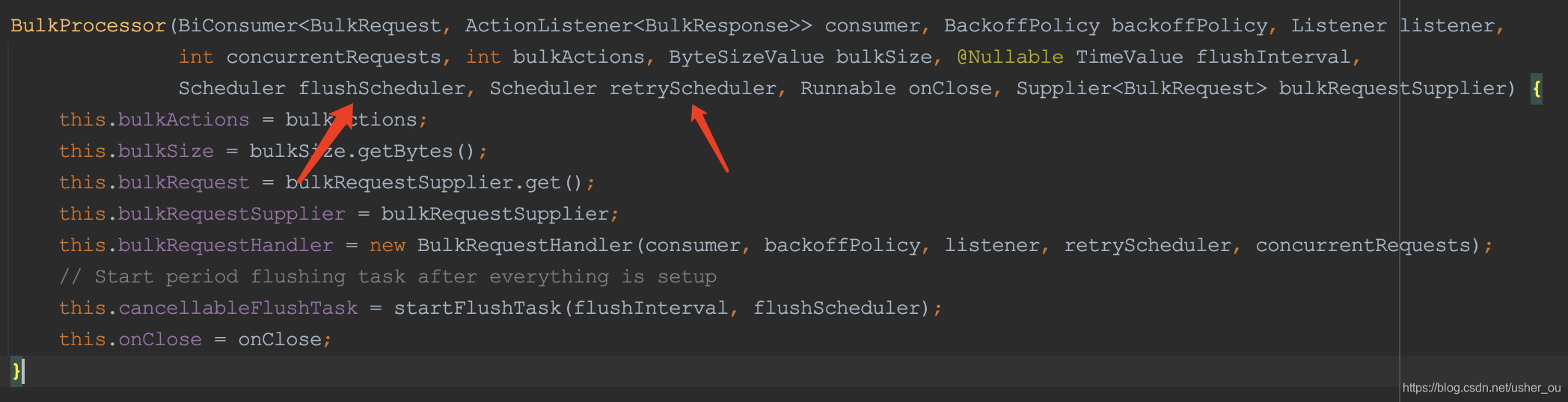
如上图所示,elasticsearch在7.6.0版本优化了初始化BulkProcessor的Scheduler参数,将刷新和重试的Scheduler对象分别用了不同的对象。



